
Word2Vec是语言模型中的一种,它是从大量文本预料中以无监督方式学习语义知识的模型,被广泛地应用于自然语言处理中。
word2vec一共分为2种网络结构,2种采样方式,一共4个模型。
- 两个算法:continuous bag-of-words(CBOW)和 skip-gram。
- CBOW 是根据中⼼词周围的上下⽂单词来预测该词的词向量。
- skip-gram 则相反,是根据中⼼词预测周围上下⽂的词的概率分布。
- 两个训练⽅法:negative sampling 和 hierarchical softmax。
- Negative sampling 通过抽取负样本来定义⽬标,
- hierarchical softmax 通过使⽤⼀个有效的树结构来计算所有词的概率来定义⽬标。
word2vec的网络结构
Word2Vec是轻量级的神经网络,其模型仅仅包括输入层、隐藏层和输出层,模型框架根据输入输出的不同,主要包括CBOW和Skip-gram模型:
- CBOW的方式是在知道词 $w_{t}$ 的上下文 $w_{t-2},w_{t-1},w_{t+1},w_{t+2}$的情况下预测当前词 $w_{t}$
- Skip-gram是在知道了词 $w_{t}$ 的情况下,对词 $w_{t}$ 的上下 文 $w_{t-2},w_{t-1},w_{t+1},w_{t+2}$ 进行预测,如下图所示:
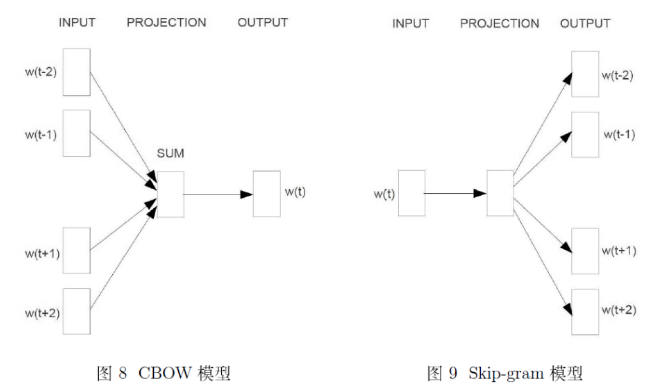
cbow
Simple CBOW Model
为了更好的了解模型深处的原理,我们先从Simple CBOW model(仅输入一个词,输出一个词)框架说起。
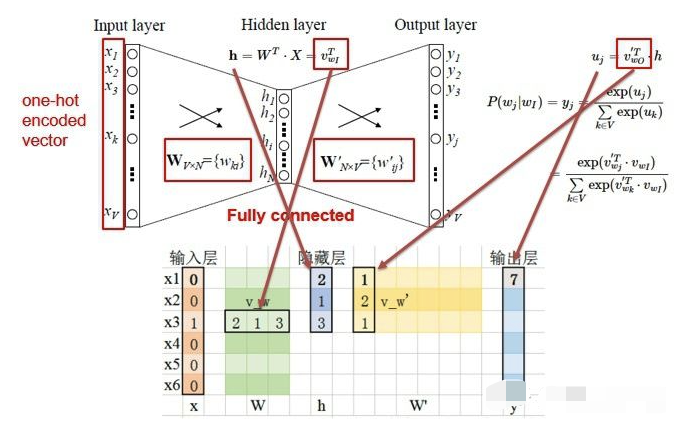
如上图所示:
-
input layer输入的X是单词的
one-hot representation(考虑一个词表V,里面的每一个词 $w_{i}$ 都有一个编号$i \in {1,…V}$,那么词 $w_{i}$ 的one-hot表示就是一个维度为$V$的向量,其中第i个元素值非零,其余元素全为0,例如: $w_{2} = [0,1,0,0,0]^T$; - 输入层到隐藏层之间有一个权重矩阵W,隐藏层得到的值是由输入X乘上权重矩阵得到的(细心的人会发现,0-1向量乘上一个矩阵,就相当于选择了权重矩阵的某一行,如图:输入的向量X是[0,0,1,0,0,0],W的转置乘上X就相当于从矩阵中选择第3行[2,1,3]作为隐藏层的值);
- 隐藏层到输出层也有一个权重矩阵W’,因此,输出层向量y的每一个值,其实就是隐藏层的向量点乘权重向量W’的每一列,比如输出层的第一个数7,就是向量[2,1,3]和列向量[1,2,1]点乘之后的结果;
- 最终的输出需要经过softmax函数,将输出向量中的每一个元素归一化到0-1之间的概率,概率最大的,就是预测的词。
了解了Simple CBOW model的模型框架之后,我们来学习一下其目标函数
输出层通过softmax归一化,u代表的是输出层的原始结果。通过下面公式,我们的目标函数可以转化为现在这个形式
CBOW Multi-Word Context Model
了解了Simple CBOW model之后,扩展到CBOW就很容易了,只是把单个输入换成多个输入罢了(划红线部分)。
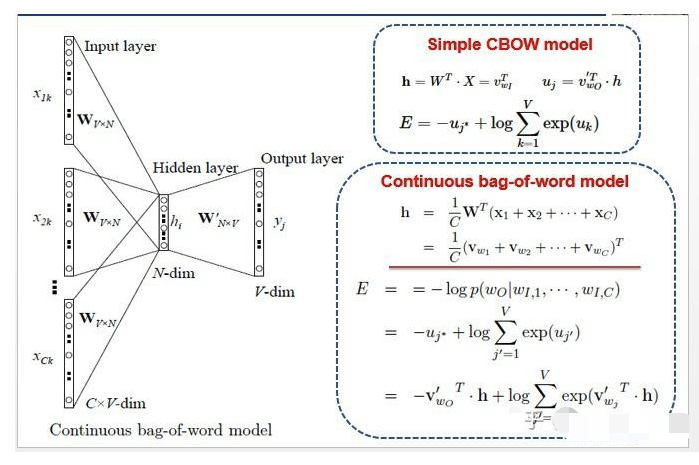
对比可以发现,和simple CBOW不同之处在于,输入由1个词变成了C个词,每个输入 $X_{ik}$ 到达隐藏层都会经过相同的权重矩阵W,隐藏层h的值变成了多个词乘上权重矩阵之后加和求平均值。
Skip-gram
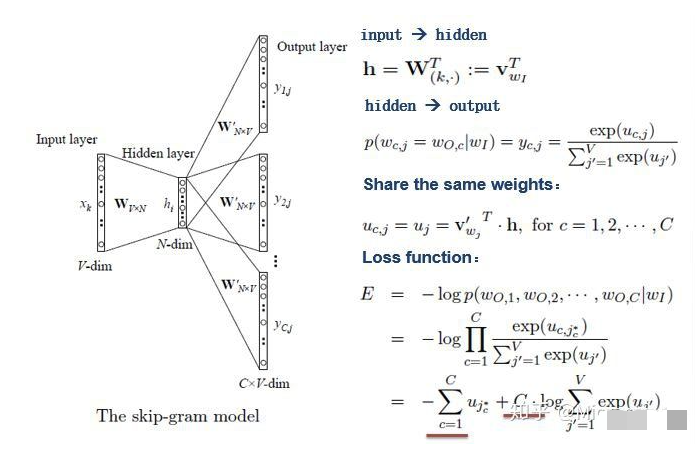
如上图所示,Skip-gram model是通过输入一个词去预测多个词的概率。输入层到隐藏层的原理和simple CBOW一样,不同的是隐藏层到输出层,损失函数变成了C个词损失函数的总和,权重矩阵W'还是共享的。
一般神经网络语言模型在预测的时候,输出的是预测目标词的概率,也就是说我每一次预测都要基于全部的数据集进行计算,这无疑会带来很大的时间开销。不同于其他神经网络,Word2Vec提出两种加快训练速度的方式,一种是Hierarchical softmax,另一种是Negative Sampling
基于Hierarchical Softmax的模型
基于层次Softmax的模型主要包括输入层、投影层(隐藏层)和输出层,非常的类似神经网络结构。对于Word2Vec中基于层次Softmax的CBOW模型,我们需要最终优化的目标函数是 :
其中 $Context(w)$ 表示的是单词 $w$ 的的上下文单词。而基于层次Softmax的Skip-gram模型的最终需要优化的目标函数是:
基于Hierarchical Softmax的cbow
层次Softmax的CBOW的结构
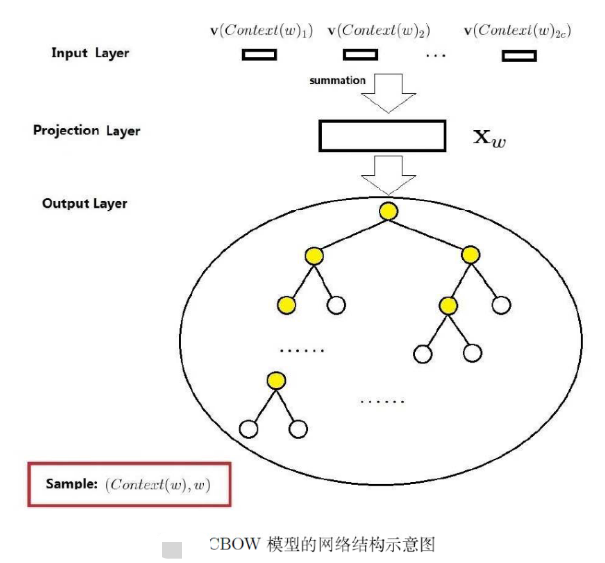
给出了基于层次Softmax的CBOW的整体结构,首先它包括输入层、投影层和输出层:
-
输入层:是指$Context(w)$ 中所包含的
2c个词的词向量 -
投影层:指的是直接对
2c个词向量进行累加,累加之后得到下式: -
输出层:是一个Huffman树,以语料中出现过的词当叶子结点,各词在语料中出现过的次数当权值构建出来的二叉树。其中叶子节点共N个,对应于N个单词,非叶子节点N-1个(对应上图中标成黄色的结点)。Word2Vec基于层次Softmax的方式主要的精华部分都集中在了哈夫曼树这部分,下面详细介绍
CBOW的目标函数
为了便于下面的介绍和公式的推导,这里需要预先定义一些变量:
- $p^w$ :从根节点出发,然后到达单词 $w$ 对应叶子结点的路径。
- $l^w$ :路径 $p^w$ 中包含的结点的个数。
- $p^w_1, p^w_2, …, p^w_{l^w}$ : 路径 $p^w$中对应的各个结点,其中 $p_{1}^w$代表根结点,而 $p_{l_{w}}^w$代表的是单词 $w$对应的结点。
- $d^w_2, d^w_3 …, d^w_{l^w}\in {0, 1 }$ : 单词 $w$ 对应的哈夫曼编码,一个词的哈夫曼编码是由 $l^w-1$ 位构成的, 表示$d_{j}^w$路径 $p^w$ 中的第j个单词对应的哈夫曼编码,根结点不参与对应的编码。
- $\theta^w_1, \theta^w_2, …, \theta^w_{l^w-1}\in \Re^{m}$ : 路径 $p^w$中非叶子节点对应的向量, $\theta_{j}^w$表示路径 $p^w$ 中第 $j$ 个非叶子节点对应的向量。 这里之所以给非叶子节点定义词向量,是因为这里的非叶子节点的词向量会作为下面的一个辅助变量进行计算,在下面推导公式的时候就会发现它的作用了。
我们考虑单词w=”足球”的情形。下图中红色线路就是我们的单词走过的路径,整个路径上的5个结点就构成了路径 $p^w$ ,其长度 $l^w = 5$ ,然后 $p^w_1, p^w_2,p^w_3,p^w_4,p^w_{5}$ 就是路径 上的五$p^w$个结点,其中 $p_{1}^w$ 对应根结点。 $d^w_2,d^w_3,d^w_4,d^w_5$分别为1,0,0,1,即”足球”对应的哈夫曼编码就是1001。最后 $\theta^w_1, \theta^w_2, \theta^w_3,\theta^w_4$就是路径 $p^w$ 上的4个非叶子节点对应的向量。
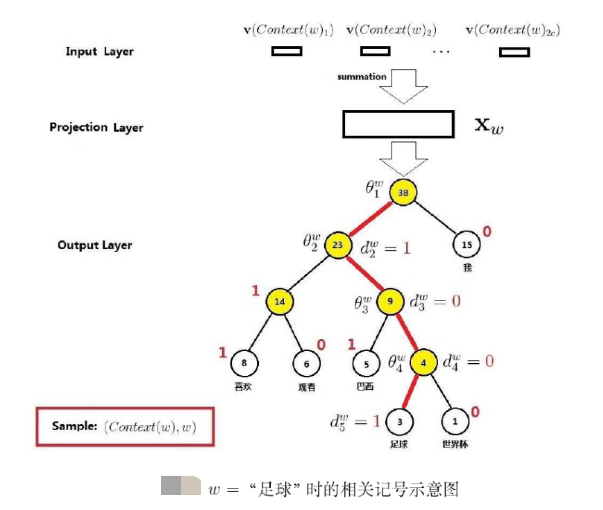
下面我们需要开始考虑如何构建条件概率函数 $p(w\Context(w))$ ,以上面的w=”足球”为例,从根节点到”足球”这个单词,经历了4次分支,也就是那4条红色的线,而对于这个哈夫曼树而言,每次分支相当于一个二分类。
既然是二分类,那么我们可以定义一个为正类,一个为负类。我们的”足球”的哈夫曼编码为1001,这个哈夫曼编码是不包含根节点的,因为根节点没法分为左还是右子树。那么根据哈夫曼编码,我们一般可以把正类就认为是哈夫曼编码里面的1,而负类认为是哈夫曼编码里面的0。不过这只是一个约定而已,因为哈夫曼编码和正类负类之间并没有什么明确要求对应的关系。事实上,Word2Vec源码中将编码为1的认定为负类,而编码为0的认定为正类,也就是说如果分到了左子树,就是负类;分到了右子树,就是正类。那么我们可以定义一个正类和负类的公式:
简而言之就是,将一个结点进行分类时,分到左边就是负类,分到右边就是正类。
在进行二分类的时候,这里选择了Sigmoid函数。那么,一个结点被分为正类的概率就是:
被分为负类的概率就是 。注意,公式里面包含的有
,这个就是非叶子对应的向量
。
对于从根节点出发到达“足球”这个叶子节点所经历的4次二分类,将每次分类的概率写出来就是:
- 第一次分类:
- 第二次分类:
- 第三次分类:
- 第四次分类:
但是,我们要求的是 ,即
,它跟这4个概率值有什么关系呢?关系就是:
至此,通过w=”足球”的小例子,Hierarchical Softmax的基本思想就已经介绍完了
小结一下:对于词典中的任意一个单词 ,哈夫曼树中肯定存在一条从根节点到单词
对应叶子结点的路径
,且这条路径是唯一的。路径
上存在
个分支,将每个分支看做一次二分类,每一次分类就产生一个概率,将这些概率乘起来,就是所需要的
。
条件概率 的一般公式可写为:
其中:
或者写成整体表达式:
最终loss函数(目标函数):
为了梯度推导方便起见,将上式中双重求和符号里面的内容简记为 ,即
已经推导出了CBOW模型的目标函数公式,接下来就是讨论如何优化它,即如何将这个函数最大化。Word2Vec里面采用的是随机梯度上升法。而梯度类算法的关键是给出相应的梯度计算公式,进行反向传播
参数更新
首先考虑\(L(w,j)\)关于 的梯度计算:
于是, 的更新公式可写为:
接下来考虑\(L(w,j)\)关于 的梯度:
到了这里,我们已经求出来了 的梯度,但是我们想要的其实是每次进行运算的每个单词的梯度,而
是
中所有单词累加的结果,那么我们怎么使用
来对
中的每个单词
进行更新呢?这里原作者选择了一个简单粗暴的方式,直接使用
的梯度累加对
进行更新:
通俗理解
基于Hierarchical Softmax的cbow的流程:
- 给定一个窗口的训练词汇(单侧窗口宽度为
c),中心词为$x_{t}$,用中心词的两边词计算向量$x_{w}$近似中心词向量$ x_{t}$: - 构建Huffman树:以语料中出现过的词当叶子结点,各词在语料中出现过的次数当权值构建出来的二叉树。其中叶子节点共N个,对应于N个单词,非叶子节点N-1个。Huffman树中的所有节点都表示为一个向量
- 寻找中心词路径:从根结点出发,寻找到目标节点$x_{t}$的一个路径$p^{w}$,
: 路径
中对应的各个结点,其中
代表根结点,而
代表的是单词
对应的结点
- 路径中的每一个节点都是一个样本,表示一个分类问题,用$x_{w}$与$p_{i}^{w}$内积表示目标节点与当前路径的分类结果,每一次分类就产生一个概率,将这些概率乘起来,就是所需要的
- 暂时规定Huffman树编码向左为正例,向右为负例(规定左正还是右正不影响):实际上 路径中的每个样本 $p_{i}^{w}$与 $x_{w}$进行内积再过sigmoid 得到predict,对应label为路径的Huffman树编码,直接求交叉熵即可。
基于Hierarchical Softmax的skip-gram
基于Hierarchical Softmax的Skip-gram模型网络结构
下图给出了Skip-gram模型的网络结构,同CBOW模型的网络结构一样,它也包括三层:输入层、投影层和输出层。下面以样本 为例,对这三层做简要说明。
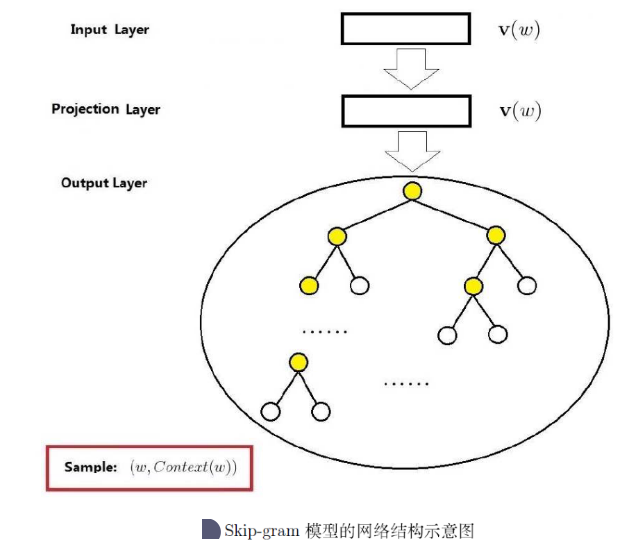
- 输入层:只含当前样本的中心词
。
- 投影层:这是个恒等投影,把
投影到
- 输出层:和CBOW模型一样,输出层也是一颗Huffman树。
Skip-gram的目标函数
对于Skip-gram模型,已知的是当前词 ,需要对其上下文
中的词进行预测,因此目标函数应该形如公式(7),且关键是条件概率函数
的构造,Skip-gram模型中将其定义为:
上式中 可按照上小节介绍的Hierarchical Softmax思想,类似于公式(8),可写为:
其中:
将公式(10)依次代回,可得对数似然函数公式(7)的具体表达式:
同样,为了梯度推导方便,将三重求和符号里的内容简记为 ,即:
至此,已经推导出了Skip-gram模型的目标函数(公式11),接下来同样利用随机梯度上升法对其进行优化。而梯度类算法的关键是给出相应的梯度计算公式,进行反向传播
参数更新
首先考虑\(L(w,u,j)\)关于 的梯度计算:
于是, 的更新公式可写为:
同理,根据对称性,可以很容易得到 关于
的梯度:
我们也可以得到关于v(w)的更新公式:
通俗理解
基于Hierarchical Softmax的skip-gram的流程:
- 给定一个窗口的训练词汇(单侧窗口宽度为
c),中心词为$x_{w}$,用中心词向量$x_{w}$计算窗口周边词向量$u_{i}$: - 构建Huffman树:以语料中出现过的词当叶子结点,各词在语料中出现过的次数当权值构建出来的二叉树。其中叶子节点共N个,对应于N个单词,非叶子节点N-1个。Huffman树中的所有节点都表示为一个向量
- 寻找中心词路径:从根结点出发,寻找到每一个周边词$u_{i}$的一个路径$p^{u}$,\(p_{1}^{u},p_{2}^{u},p_{3}^{u},....p_{l}^{u}\) : 路径$p^{u}$中对应的各个结点,其中
-
对每个周边词路径:路径中的每一个节点都是一个样本,表示一个分类问题,用$x_{w}$与$p_{i}^{u}$内积表示目标节点与当前路径的分类结果,每一次分类就产生一个概率,将这些概率乘起来,就是所需要的$$p(Context(w) w)$$ - 暂时规定Huffman树编码向左为正例,向右为负例(规定左正还是右正不影响):实际上 路径中的每个样本 $p_{i}^{w}$与 $x_{w}$进行内积再过sigmoid 得到predict,对应label为路径的Huffman树编码,直接求交叉熵即可。
基于Negative Sampling的模型
本节将介绍基于Negative Sampling的CBOW和Skip-gram模型。Negative Sampling(简称为NEG)是Tomas Mikolov等人在论文《Distributed Representations of Words and Phrases and their Compositionality》中提出的,它是NCE(Noise Contrastive Estimation)的一个简化版,目的是用来提高训练速度并改善所得词向量的质量。与Hierarchical Softmax相比,NEG不再使用复杂的Huffman树,而是利用相对简单的随机负采样,能大幅度提高性能,因而可作为Hierarchical Softmax的一种替代。
NCE 的细节有点复杂,其本质是利用已知的概率密度函数来估计未知的概率密度函数。简单来说,假设未知的概率密度函数为X,已知的概率密度为Y,如果得到了X和Y的关系,那么X也就可以求出来了。具体可以参考论文《 Noise-contrastive estimation of unnormalized statistical models, with applications to natural image statistics》
负采样算算法
词典D中的词在语料C中出现的次数有高有底,对于那些高频词,被选为负样本的概率就应该比较大,反之,对于那些低频词,其被选中的概率就应该比较小。这就是我们对采样过程的一个大致要求,本质上就是一个带权采样问题。
下面,先用一段通俗的描述带权采样的机理。设词典D中的每一个词w对应一个线段 ,长度为:
这里 表示一个词在语料C中出现的次数(分母中的求和项用来做归一化)。现在将这些线段首尾相连地拼接在一起,形成一个长度为1的单位线段。如果随机地往这个单位线段上打点,则其中长度越长的线段(对应高频词)被打中的概率就越大
接下来再谈谈Word2Vec中的具体做法:
记 ,这里
表示词典中的第j个单词,则以
为剖分结点可得到区间
上的一个非等距剖分,
为其N个剖分区间。进一步引入区间
上的一个等距离剖分,剖分结点为
,其中
,具体见下面给出的示意图。
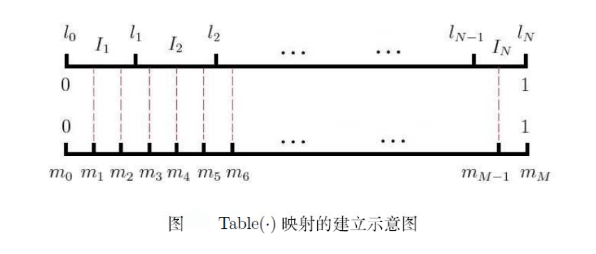
将内部剖分结点 投影到非等距剖分上,如上图中的红色虚线所示,则可建立
与区间
(或者说
)的映射关系。
有了这个映射,采样就简单了:每次生成一个 间的随机整数r,Table(r)就是一个样本。当然,这里还有一个细节,当对
进行负采样时,如果碰巧选到
自己该怎么办?那就跳过去,Word2Vec的代码中也是这么处理的。
值得一提的是,Word2Vec源码中为词典D中的词设置权值时,不是直接用counter(w),而是对其做了 次幂,其中
,即公式(12)变成了:
此外,代码中取 ,源代码中是变量table_size。而映射公式(13)则是通过一个名为InitUnigramTable的函数来完成。
基于Negative Sampling的cbow
基于Negative Sampling的CBOW的目标函数
推导出基于Negative Sampling的CBOW的目标函数:
首先我们先选好一个关于 的负样本子集
,对于
,我们定义单词
的标签为:
上式表示词 的标签,即正样本的标签为1,负样本的标签为0。
对于一个给定的正样本 ,我们希望最大化的目标函数是:
其中
这里 仍表示
中各个词的词向量之和,而
在这里作为一个辅助向量,为待训练的参数。
为什么要最大化 呢?让我们先来看看g(w)的表达式,将公式(15)带入公式(14),有:
其中, 表示当上下文为
时,预测中心词为w的概率,而
则表示当上下文为
时,预测中心词为u的概率,这里可以看一个二分类问题。从形式上看,最大化
,相当于最大化
,同时最小化所有的
。这不正是我们希望的吗?增大正样本的概率同时降低负样本的概率。于是,对于一个给定的语料库C,有函数:
可以作为最终的整体优化目标。当然,这里为了求导方便,对G取对数,最终的目标函数就是:
同样,为了求导方便,我们还是取 :
梯度更新
接下来,利用随机梯度上升法求梯度。首先考虑L(w,u)关于 的梯度计算:
那么 的更新公式可以写成:
同时根据对称性,可以得到 的梯度:
那么 的更新公式可以写成:
通俗理解
基于Negative Sampling的cbow的流程:
- 给定一个窗口的训练词汇(单侧窗口宽度为
c),中心词为$x_{t}$,用中心词的两边词计算向量$x_{w}$近似中心词向量$ x_{t}$: - 进行负采样:基于词频进行加权采样,得到k个负样本$x_{i}$
- 用$x_{w}$与中心词$x_{t}$计算得到正prediction,用$x_{w}$与k个负样本$x_{i}$计算得到负prediction
- 直接求交叉熵即可
基于Negative Sampling的skip-gram
####基于Negative Sampling的 skip-gram目标函数
对于一个给定的样本 , 我们希望最大化:
其中:
或者写成整体表达式:
这里 表示处理词
时生成的负样本子集。于是,对于一个给定的语料库C,函数:
就可以作为整体优化的目标。同样,我们取G的对数,最终的目标函数就是:
为了梯度推导的方便,我们依旧将三重求和符号下的内容提取出来,记为 ,即:
梯度更新
利用随机梯度上升法求梯度。首先考虑 关于
的梯度计算:
然后得到 的更新公式:
同理根据对称性,得到:
然后得到 的更新公式:
通俗理解
基于Negative Sampling的skip-gram的流程:
- 给定一个窗口的训练词汇(单侧窗口宽度为
c),中心词为$x_{t}$,2c个周边词为$x_{p}$: - 对于每一个周边词$x_{p}$:基于词频进行加权采样,得到k个负样本$x_{pi}$
- 对每个周边词$x_{p}$:用周边词$x_{p}$与中心词$x_{t}$计算得到正prediction,用$x_{t}$与k个负样本$x_{pi}$计算得到负prediction
- 直接求交叉熵即可
word2vec的相关问题
- Hierarchical Softmax对词频低的和词频高的单词有什么影响?为什么?
H-S利用了Huffman树依据词频建树,词频大的节点离根节点较近,词频低的节点离根节点较远,距离远参数数量就多,在训练的过程中,低频词的路径上的参数能够得到更多的训练,所以效果会更好
-
Word2Vec有哪些局限性?
Word2Vec作为一个简单易用的算法,其也包含了很多局限性:
-
- Word2Vec只考虑到上下文信息,而忽略的全局信息;
- Word2Vec只考虑了上下文的共现性,而忽略的了彼此之间的顺序性
-
Word2vec为什么需要二次采样?
还涉及到一个采样方法,就是subsampling,中文叫做二次采样。 用最简单的一句话描述二次采样就是,对文本中的每个单词会有一定概率删除掉,这个概率是和词频有关,越高频的词越有概率被删掉。 二次采样的公式如下所示
\[p(w_{i})=max(1-\sqrt{\frac{t}{f(w_{i})})}, 0)\]注意: t为超参数,分母
f(w)为单词w的词频与总词数之比在一个背景窗口中,一个词和较低频词同时出现比和较高频词同时出现对训练词嵌入模型更有益
-
低频词的处理
将词频低于一定阈值的词进行清理掉。单词出现次数太低,根本学习不好词向量
-
高频词的处理
词频太高,热门效应明显,采样 subsampling,中文叫做二次采样
-
窗口及上下文
窗口及上下文选择:窗口一般选择 5 左右
-
自适应学习率
word2vec源码中采用自适应学习率。预先设置一个初始的学习率$\eta_{0} $(默认值0.025),每处理完10000个词就按以下公式调整:
\[\eta = \eta_{0} (1-\frac{word\_count\_actual}{train\_words+1})\]其中 $ word_count_actual $ 表示当前已经处理过的词数,$train_words=\sum_{w\in D}count(w) $, +1 是为了防止分母为0
word2vec实践
参数
Skip-Gram 的速度比CBOW慢一点,小数据集中对低频次的效果更好;
Sub-Sampling Frequent Words可以同时提高算法的速度和精度,Sample 建议取值为[10-5, 10-3] ;
Hierarchical Softmax对低词频的更友好;
Negative Sampling对高词频更友好;
向量维度一般越高越好,但也不绝对;
Window Size,Skip-Gram一般10左右,CBOW一般为5左右。
具体应用参考自己项目代码